Back to Blog
Feb 26, 2026
Written by
Simon Spurrier

Every morning, one of us opens BetterStack, scrolls through errors from the last 24 hours, and tries to separate signal from noise. Most are transient — network timeouts, third-party API blips, rate limits that resolve themselves. The real bugs hide underneath. By the time we've read stack traces, checked frequency, assessed user impact, and context-switched to the codebase, an hour is gone. It's important work but never urgent, so it gets skipped, and errors accumulate.
We wanted a full-time SRE — but we're a small startup with limited resources. The ideal: a fully autonomous system that finds and fixes production issues without human involvement. But AI agents are still earning trust, and we wanted to get comfortable with ours before handing over the keys. So we built the first version with human-in-the-loop approval and a clear path to full autonomy.
Build vs. Buy — and What That Means for SaaS
There's a growing narrative that LLMs are killing SaaS. We don't think we're quite there yet but the nuance matters.
We had all the pieces already: BetterStack's MCP server to query errors programmatically, our own agent framework with tool use and streaming, Daytona sandboxes for isolated code execution, an LLM adapter layer, and a Slack bot. The total new code was ~1,200 lines of glue. From first commit to deployed in production: two days.
But — we're still paying for BetterStack. Their core product (error tracking, log aggregation, uptime monitoring) represents years of engineering we couldn't replicate. The MCP server just gave us a programmatic interface to that value. Same story with Daytona — we're using their sandboxes, not building our own.
Here's where it gets interesting: BetterStack actually offers their own AI SRE agent product. We could have bought it. Instead, we built our own in two days — because we already had the agent framework, the sandbox infrastructure, and the Slack integration. The marginal effort was minimal.
That complicates the "is SaaS dead?" narrative further. It's not just that LLMs make the orchestration layer easy to build. It's that teams with existing agent infrastructure can replicate feature-level additions to SaaS products faster than the vendor can ship them — at least for their own specific workflow. BetterStack's SRE agent is a general-purpose product that works for everyone. Ours is tailored to our codebase, our triage preferences, our deployment pipeline. Both are valid, but one took two days and fits like a glove.
The nuanced take: LLMs threaten SaaS products that are mostly glue (dashboards, simple automations, CRUD wrappers). But products with genuine core value — deep data pipelines, specialized infrastructure, complex domain logic — aren't threatened anytime soon. If anything, MCP makes them more valuable by making them composable. The new risk for SaaS is at the feature layer: when your platform exposes good APIs, customers can build custom workflows on top faster than you can ship generic ones.
We didn't replace BetterStack. We made it 10x more useful by plugging it into an agent.
How It Works
The system has two stages — triage and fix — separated by a human decision in Slack.
Stage 1: Triage. Every morning at 6 AM (or on demand via a /trigger endpoint), the triage agent wakes up and connects to BetterStack through MCP. It pulls error patterns from the last 24 hours, checks which ones already have fixes in progress, and fetches stack traces and request context for the rest. It classifies each error — code bug, config issue, noisy reporting, transient, external dependency, or needs investigation — and ranks them by user impact. The top 5 get posted to Slack as individual cards, each showing the classification, error details, frequency, affected users, and a hypothesis for how to fix it. Low-signal noise (infrequent errors with minimal user impact) and transient issues get filtered out automatically.
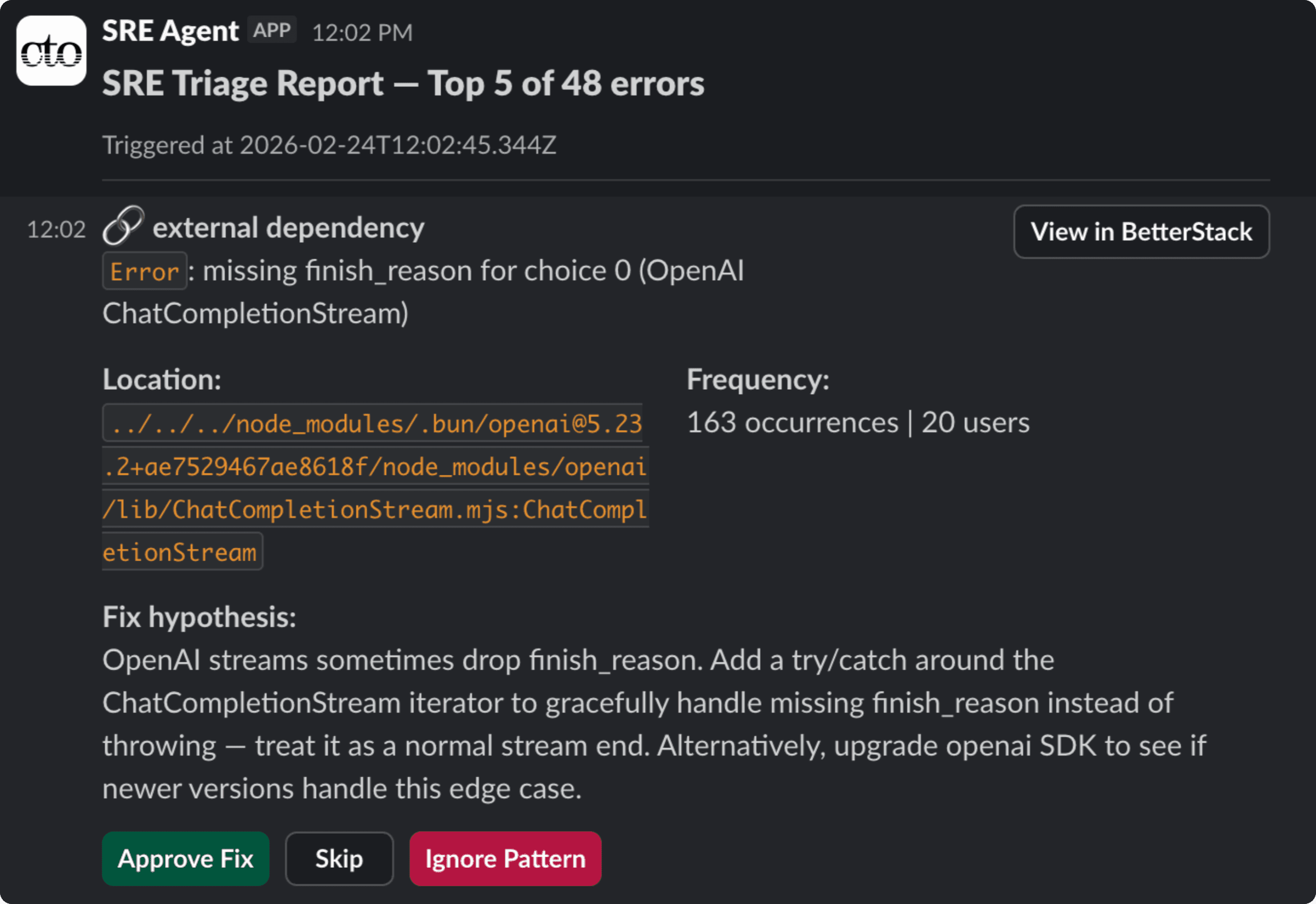
The human gate. Each Slack card has three buttons: Approve Fix, Skip, and Ignore Pattern. Approve opens a modal where the reviewer can add a note — context the fix agent should know, like "this only happens for free-tier users" or "check the webhook handler, not the caller." Skip moves on. Ignore marks the pattern in BetterStack so it won't surface again.
Stage 2: Fix. When a fix is approved, a fix agent spins up in a fresh Daytona sandbox. It clones the repo, creates a branch, installs dependencies, and gets to work. The system prompt includes the error context, classification, triage hypothesis, and the reviewer's note. The fix agent reads the relevant source files, makes the minimal change needed, then calls a finish tool that automatically runs type-checking and lint/format fixes. If validation fails, the error goes back to the agent to try again. Once it passes, the agent commits, pushes, and opens a PR — with the root cause analysis, summary of changes, and a link back to the Slack thread. The Slack card updates in place to show the PR link and a completion status.
The whole loop — from error detected to PR ready for review — runs without anyone opening an IDE.
The Architecture — Why Reusable Libraries Made This Possible
The reason we could build this in two days is our monorepo's port/adapter architecture. Everything — LLM providers, sandboxes, agent loops, MCP clients — is abstracted behind interfaces, composed through configuration.
Here's the triage agent configuration, simplified:
A new agent type means filling in a config object, not building from scratch. The adapter pattern makes each piece independently swappable:
Sandboxis an abstract class.DaytonaSandboximplements it. If we switch providers, nothing else changes. (We wrote about that decision in Choosing an AI Sandbox Provider in 2026.)LlmCalleris an abstract class. Provider adapters implementdoCall(). The agent loop never knows which LLM it's talking to.AgentConfigurationcomposes all of these. Tools, prompts, loop behavior, state management — all pluggable.
We pull reusable functionality into internal libraries (@engine-labs/agent, @engine-labs/sandbox, @engine-labs/llm, etc.). The SRE agent imported these directly — no fork, no copy-paste. The monorepo pays for itself in moments like this.
Design Decisions
Four decisions worth explaining.
Two agents, not one. We have two distinct stages separated by human approval, so two agents made sense. The triage agent is read-only analysis (capped at 20 iterations); the fix agent is write-heavy coding (up to 200). Different tools, different prompts, different risk profiles. This also means we can parallelize — one triage run might approve multiple fixes that run concurrently in separate sandboxes.
BetterStack MCP: plug and play. The BetterStack MCP server is comprehensive and well-designed. The triage agent discovers all available tools at runtime via MCP's tool listing. We didn't write a single line of BetterStack integration code. The agent can query error patterns, fetch stack traces, list applications, and update error states (marking patterns as ignored) — all through MCP. The entire BetterStack connection is six lines of config:
Slack bot over Slack MCP. We built a custom Slack bot rather than using the official Slack MCP server. The Slack MCP doesn't support the interactive UI we needed — buttons, modals, in-place card updates, threaded replies. A proper Slack bot with the Web API gave us a much richer experience: triage cards with classification emojis, approve/skip/ignore buttons, a modal for adding notes before approval, and status updates that replace the buttons inline as fixes progress.
Classification-aware fixing. The triage agent classifies errors into categories — code bug, config issue, reporting level, transient, external, needs investigation. The fix prompt changes based on classification. For "adjust reporting" errors — where the bug is that an expected error reaches error tracking at the wrong level — the prompt explicitly says: don't change business logic, just fix the reporting. This prevents well-meaning but destructive "fixes."
Cron plus manual trigger. The agent runs on a schedule (daily at 6 AM) but also exposes a /trigger endpoint for on-demand runs. The triage agent surfaces only the top 5 errors ranked by user impact, so humans don't get overwhelmed and the agent stays useful.
The Road to Autonomy
Where we are now: A human approves each fix via Slack. The fix agent opens a PR but doesn't iterate on review feedback — if follow-up is needed, a developer takes over (with whatever AI-powered stack they normally use for development). This is deliberately conservative for v1.
Next step: autonomous PR iteration. Right now, if a PR needs follow-up, a developer takes over. When the fix agent can respond to review comments and push follow-up commits, we close a big gap. Our main product (cto.new) already handles this workflow — the SRE agent was intentionally kept separate to stay cleanly isolated, but we'll port those capabilities over.
After that: drop Slack approval. For low-risk fixes (reporting-level changes, lint fixes), skip the human gate entirely. Keep PR creation as the handover point — a developer still reviews before merge, but the agent doesn't need permission to attempt the fix.
Eventually: merge without human review. The dream isn't removing review — it's removing human review. An agent reviews the PR, runs automated QA, checks metrics post-deploy, and triggers follow-up commits if needed. Humans monitor the system rather than each individual fix. The foundation for this is robust CI/CD and automated testing — the agent needs to prove its changes are safe through the same pipeline any developer's code goes through. That's the vision — not a reckless autonomous agent, but one embedded in a system of automated checks that earns trust through reliability.
Wrapping Up
We didn't set out to replace SaaS tools — we made them composable. BetterStack finds the errors. Our agent triages them. Daytona provides the sandbox. The LLM does the reasoning. Slack provides the human interface. Each service does what it's best at.
The interesting part isn't any one piece — it's how quickly you can wire them together when your codebase is designed for it. Two days, ~1,200 lines, and we have an AI SRE that handles the work nobody wanted to do.